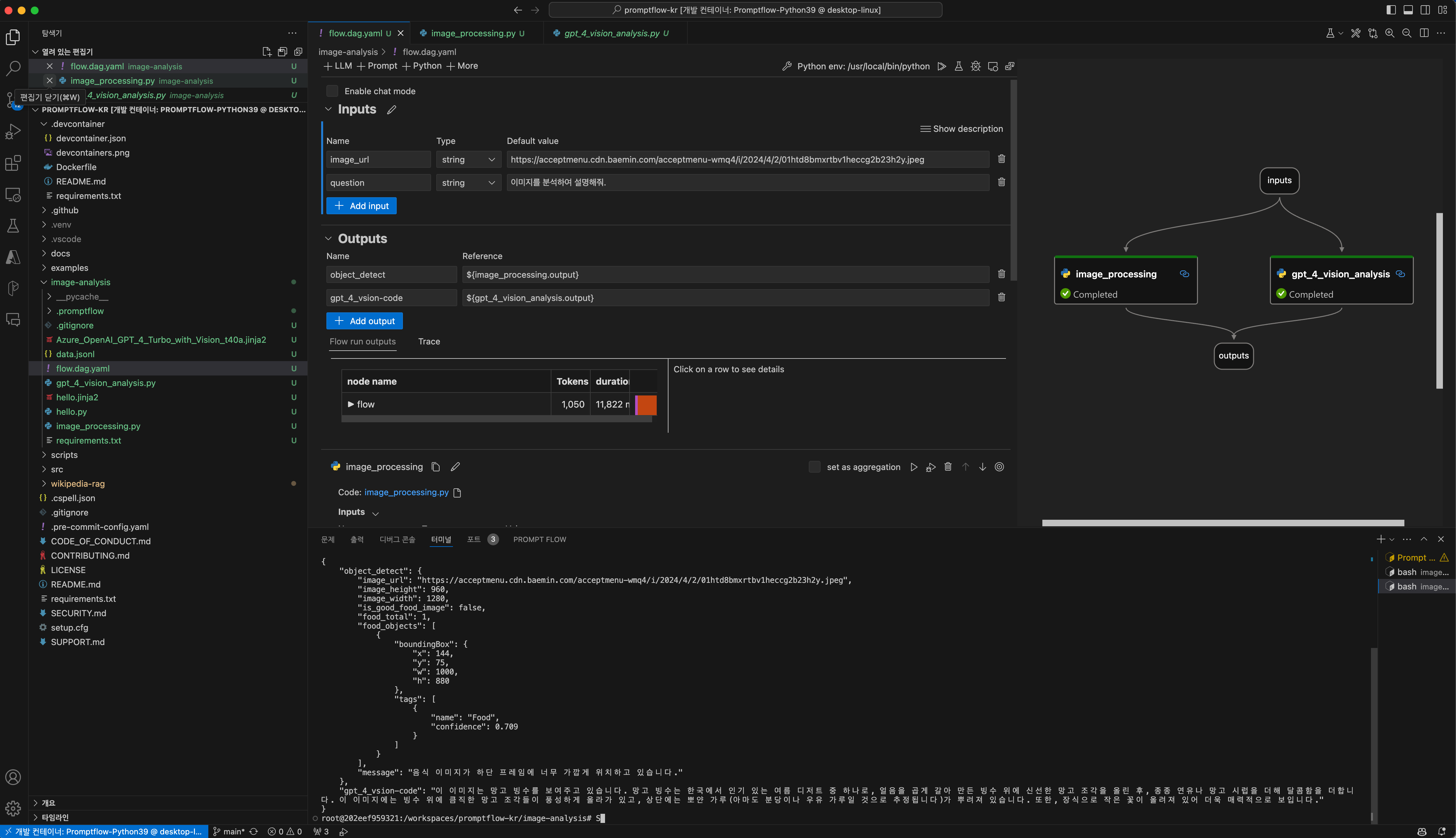
이미지 분석의 예시입니다.
GPT-4 Turbo with Vision (Enhancements)
아래는 Azure OpenAI의 GPT-4-VISION API와 Azure Compute Vision의 Obejct Detection API를 활용하는 사례입니다.
Azure의 Compute Vision API의 경우, 실행하는 Plyaground와 동일한 리전이며 유료 모델일 경우 활성화 됩니다. (예시는 Australia로 테스트한 화면입니다.)
Ouput의 형태를 보면, 이미지에 대한 설명과 객체에 대한 좌표 값이 전달 되는 것을 볼 수 있습니다. 이 값을 활용하여 더 정확한 이미지 분석이 가능합니다.
위와 같이 활용할 경우, 특별한 요금이 적용됨을 미리 알려 드립니다.
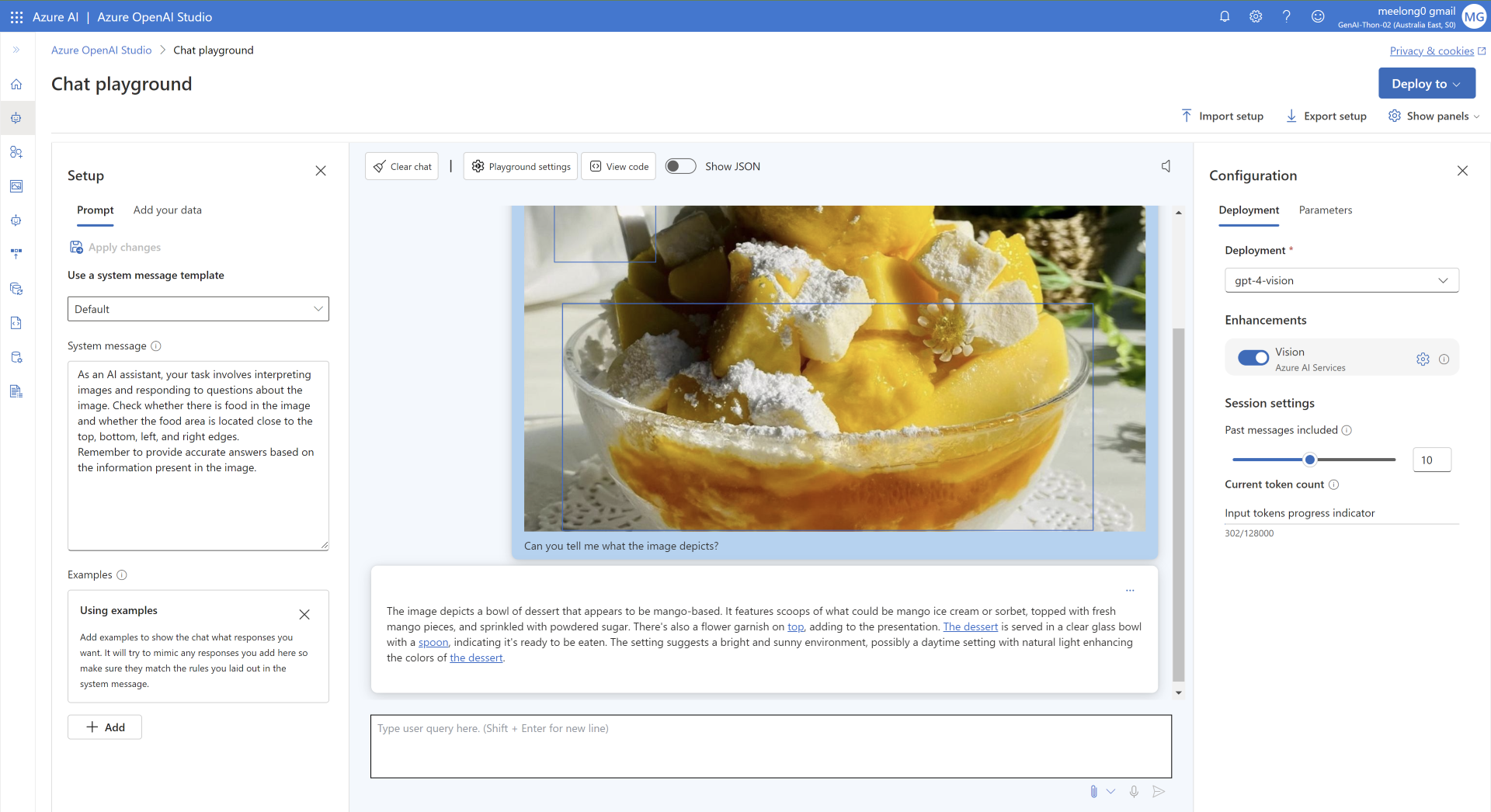
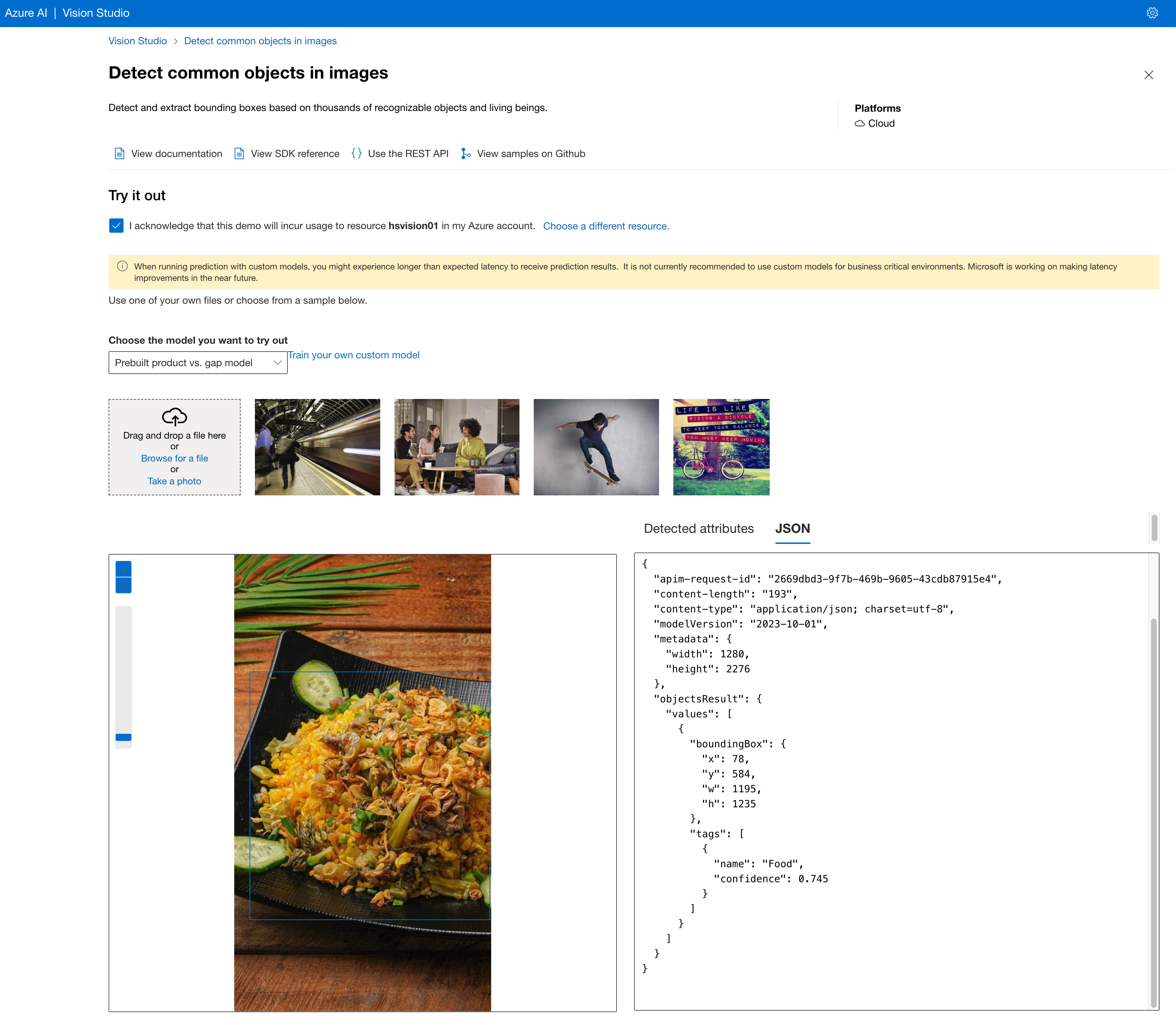
Azure Compute Vision API를 사용한 경우
Object Detection을 수행할 경우, 아래와 같이 분석 결과를 받을 수 있습니다.

{
"apim-request-id": "3b01cb13-7576-4004-8185-8d416fadf3ed",
"content-length": "288",
"content-type": "application/json; charset=utf-8",
"modelVersion": "2023-10-01",
"metadata": {
"width": 1280,
"height": 960
},
"objectsResult": {
"values": [
{
"boundingBox": {
"x": 832,
"y": 15,
"w": 408,
"h": 334
},
"tags": [
{
"name": "Vegetable",
"confidence": 0.51
}
]
},
{
"boundingBox": {
"x": 144,
"y": 75,
"w": 1000,
"h": 880
},
"tags": [
{
"name": "Food",
"confidence": 0.709
}
]
}
]
}
}

{
"apim-request-id": "73f48582-75f6-48ab-8b5c-a14a8ceaa476",
"content-length": "291",
"content-type": "application/json; charset=utf-8",
"modelVersion": "2023-10-01",
"metadata": {
"width": 3464,
"height": 3464
},
"objectsResult": {
"values": [
{
"boundingBox": {
"x": 710,
"y": 133,
"w": 2560,
"h": 3237
},
"tags": [
{
"name": "Food",
"confidence": 0.795
}
]
},
{
"boundingBox": {
"x": 609,
"y": 1865,
"w": 1570,
"h": 1473
},
"tags": [
{
"name": "Food",
"confidence": 0.715
}
]
}
]
}
}
해당 이미지는 너무 꽉 찬 음식 사진이라서 해당 이미지 근처에 여백을 늘린 후에 재시도 해야 이미지를 정확히 인식하게 됩니다.

{
"apim-request-id": "fa47f938-70f8-453a-9f2a-75c33bb924a2",
"content-length": "193",
"content-type": "application/json; charset=utf-8",
"modelVersion": "2023-10-01",
"metadata": {
"width": 1262,
"height": 1004
},
"objectsResult": {
"values": [
{
"boundingBox": {
"x": 100,
"y": 102,
"w": 1052,
"h": 767
},
"tags": [
{
"name": "Food",
"confidence": 0.779
}
]
}
]
}
}

{
"apim-request-id": "2669dbd3-9f7b-469b-9605-43cdb87915e4",
"content-length": "193",
"content-type": "application/json; charset=utf-8",
"modelVersion": "2023-10-01",
"metadata": {
"width": 1280,
"height": 2276
},
"objectsResult": {
"values": [
{
"boundingBox": {
"x": 78,
"y": 584,
"w": 1195,
"h": 1235
},
"tags": [
{
"name": "Food",
"confidence": 0.745
}
]
}
]
}
}
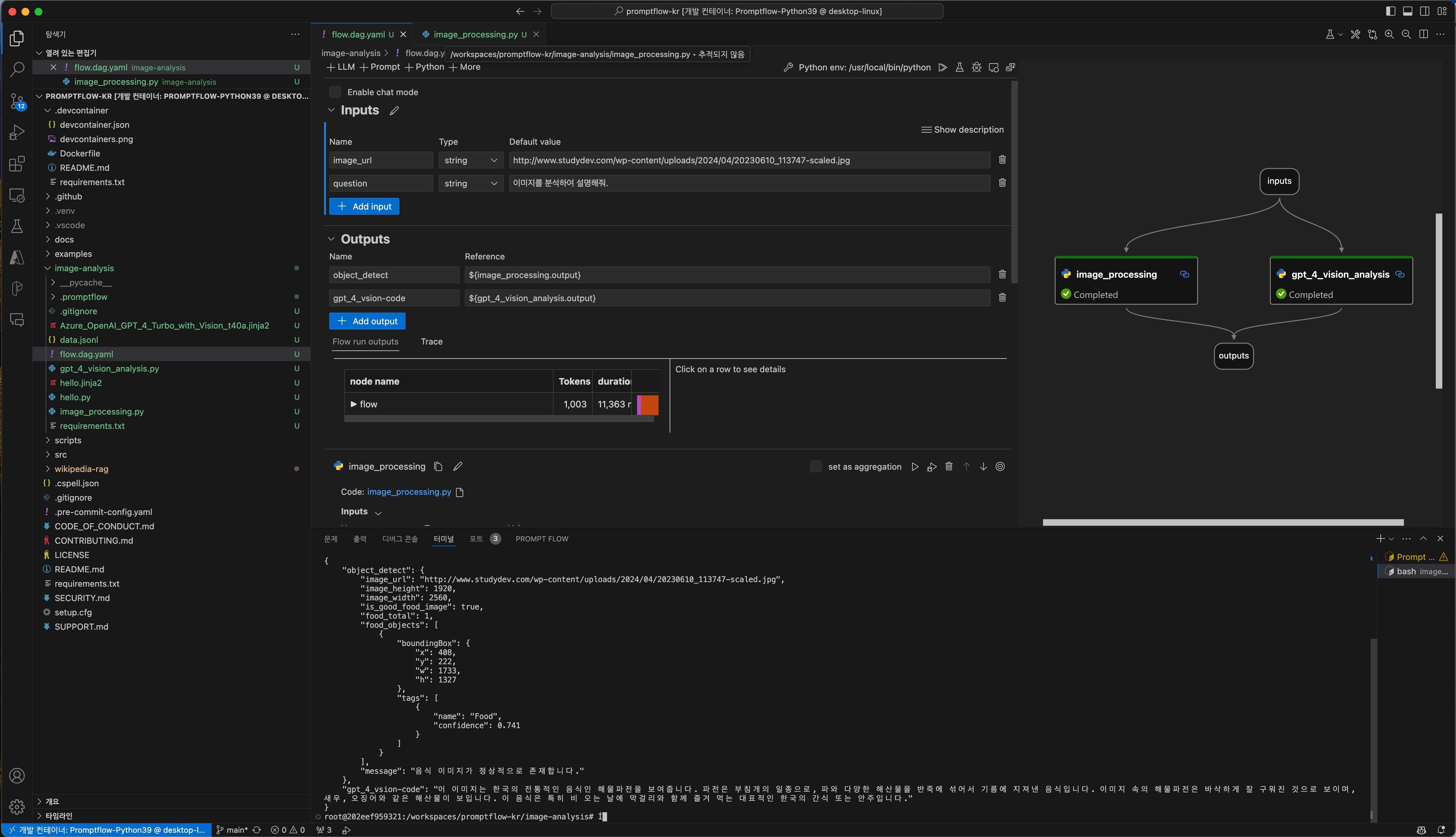
직접적으로 테스트 하는 방법입니다.
Prompt Flow를 활용하는 예시

import json
from promptflow import tool
from promptflow.client import PFClient
from azure.ai.vision.imageanalysis import ImageAnalysisClient
from azure.ai.vision.imageanalysis.models import VisualFeatures
from azure.core.credentials import AzureKeyCredential
# The inputs section will change based on the arguments of the tool function, after you save the code
# Adding type to arguments and return value will help the system show the types properly
# Please update the function name/signature per need
@tool
def image_processing(image_url: str):
# set environment variables:
pf_client = PFClient()
pf_connection = pf_client.connections.get(name="object-detection")
try:
endpoint = pf_connection.endpoint
key = pf_connection.key
except KeyError:
print("Missing environment variable 'VISION_ENDPOINT' or 'VISION_KEY'")
print("Set them before running this sample.")
exit()
# Create an Image Analysis client for synchronous operations
client = ImageAnalysisClient(
endpoint=endpoint,
credential=AzureKeyCredential(key)
)
# Get a caption for the image. This will be a synchronously (blocking) call.
result = client.analyze_from_url(
image_url=image_url,
visual_features=[VisualFeatures.OBJECTS]
).as_dict()
print(result)
image_height = result["metadata"]["height"]
image_width = result["metadata"]["width"]
food_total = 0
response_data = {
"image_url": image_url,
"image_height": image_height,
"image_width": image_width,
"is_good_food_image": True,
"food_total": 0,
"food_objects": [],
"message": ""
}
detected_position_total = []
# initialize an list dict to store the detected objects
if result["objectsResult"] is not None:
for object in result["objectsResult"]["values"]:
# 함수 호출
is_food, detected_position = position_image_food_overlap(object, image_width, image_height, 0.05)
if is_food == True:
response_data["food_objects"].append(object)
food_total += 1
if len(detected_position) > 0:
# detected_position_total에 detected_position을 추가
detected_position_total.extend(detected_position)
response_data["food_total"] = food_total
if (food_total == 0):
response_data["message"] = "음식 이미지가 존재하지 않거나 너무 확대되어진 이미지입니다."
response_data["is_good_food_image"] = False
else:
# detected_position_total에 중복된 값이 있을 경우 중복 제거
detected_position = list(set(detected_position_total))
detected_position_str = ", ".join(detected_position)
if len(detected_position) > 0:
response_data["is_good_food_image"] = False
response_data["message"] = f"음식 이미지가 {detected_position_str} 프레임에 너무 가깝게 위치하고 있습니다."
else:
response_data["message"] = "음식 이미지가 정상적으로 존재합니다."
return response_data
# If the name of a specific object is food based on the image_witdh and image_height of the image, and it is located less than 10% closer to the side of the original image based on the x, y, w, and h coordinates of the rectangle, then Function that returns location
def position_image_food_overlap(object: dict, image_width: int, image_height: int, ratio: float) -> str:
# initialize an list dict to store the detected objects
is_food = False
detected_position = []
object_area = image_width * image_height
if object["tags"][0]["name"] == "Food":
is_food = True
# 좌측 끝에 위치한 객체인지 확인
if object["boundingBox"]["x"] < image_width * ratio:
detected_position.append("좌측")
# 우측 끝에 위치한 객체인지 확인
if object["boundingBox"]["x"] + object["boundingBox"]["w"] > image_width * (1-ratio):
detected_position.append("우측")
# 상단 끝에 위치한 객체인지 확인
if object["boundingBox"]["y"] < image_height * ratio:
detected_position.append("상단")
# 하단 끝에 위치한 객체인지 확인
if object["boundingBox"]["y"] + object["boundingBox"]["h"] > image_height * (1-ratio):
print(object["boundingBox"]["y"] + object["boundingBox"]["h"])
print(image_height * (1-ratio))
detected_position.append("하단")
return is_food, detected_position
import json
from promptflow import tool
from promptflow.client import PFClient
from azure.core.credentials import AzureKeyCredential
from openai import AzureOpenAI
# The inputs section will change based on the arguments of the tool function, after you save the code
# Adding type to arguments and return value will help the system show the types properly
# Please update the function name/signature per need
@tool
def gpt_4_vision_analysis(input_url: str, question: str):
# set environment variables:
pf_client = PFClient()
pf_connection = pf_client.connections.get(name="aoai_australia")
try:
endpoint = pf_connection.api_base
key = "118a4d12a6f04dc2a4e1916770e28b5b"
except KeyError:
print("Missing environment variable 'VISION_ENDPOINT' or 'VISION_KEY'")
print("Set them before running this sample.")
exit()
api_base = endpoint
api_key= key
deployment_name = 'gpt-4-vision'
api_version = '2023-12-01-preview' # this might change in the future
client = AzureOpenAI(
api_key=api_key,
api_version=api_version,
base_url=f"{api_base}/openai/deployments/{deployment_name}"
)
response = client.chat.completions.create(
model=deployment_name,
messages=[
{ "role": "system", "content": "As an AI assistant, your task involves interpreting about the food image. Remember to provide accurate answers based on the information present in the image." },
{ "role": "user", "content": [
{
"type": "text",
"text": "이 이미지애 대해서 설명해 주세요.:"
},
{
"type": "image_url",
"image_url": {
"url": input_url
}
}
] }
],
temperature=0.1,
top_p=0.95,
max_tokens=2000
)
return response.choices[0].message.content
# system:
As an AI assistant, your task involves interpreting images and responding to questions about the image.
Remember to provide accurate answers based on the information present in the image.
# user:
Can you tell me what the image depicts?